
Although my primary area of study is compact binaries, telescopes are definitely an essential part of this. My data primarily comes from the Palomar Transient Factory (PTF), which uses the Palomar 48" Schmidt telescope (see right) to image up to 2,000 sq. deg of the sky per night. As a comparion, the moon covers about 0.2 sq. deg of the sky. We can image this wide an area because the Palomar 48" is a wide-field telescope and we image >7 sq. deg. per image.
Photometry
PTF has many science projects. Some, like discovering supernova, require fast processing that doesn't need to be perfect. Supernova (stellar explosions) are typically bright and show a large change - one night there is a blank area of the sky and the next night there's something bright there. But for stellar variability, we need very accurate precision. PTF is currently limited to an error of about 0.5% for bright sources, which is extremely good.
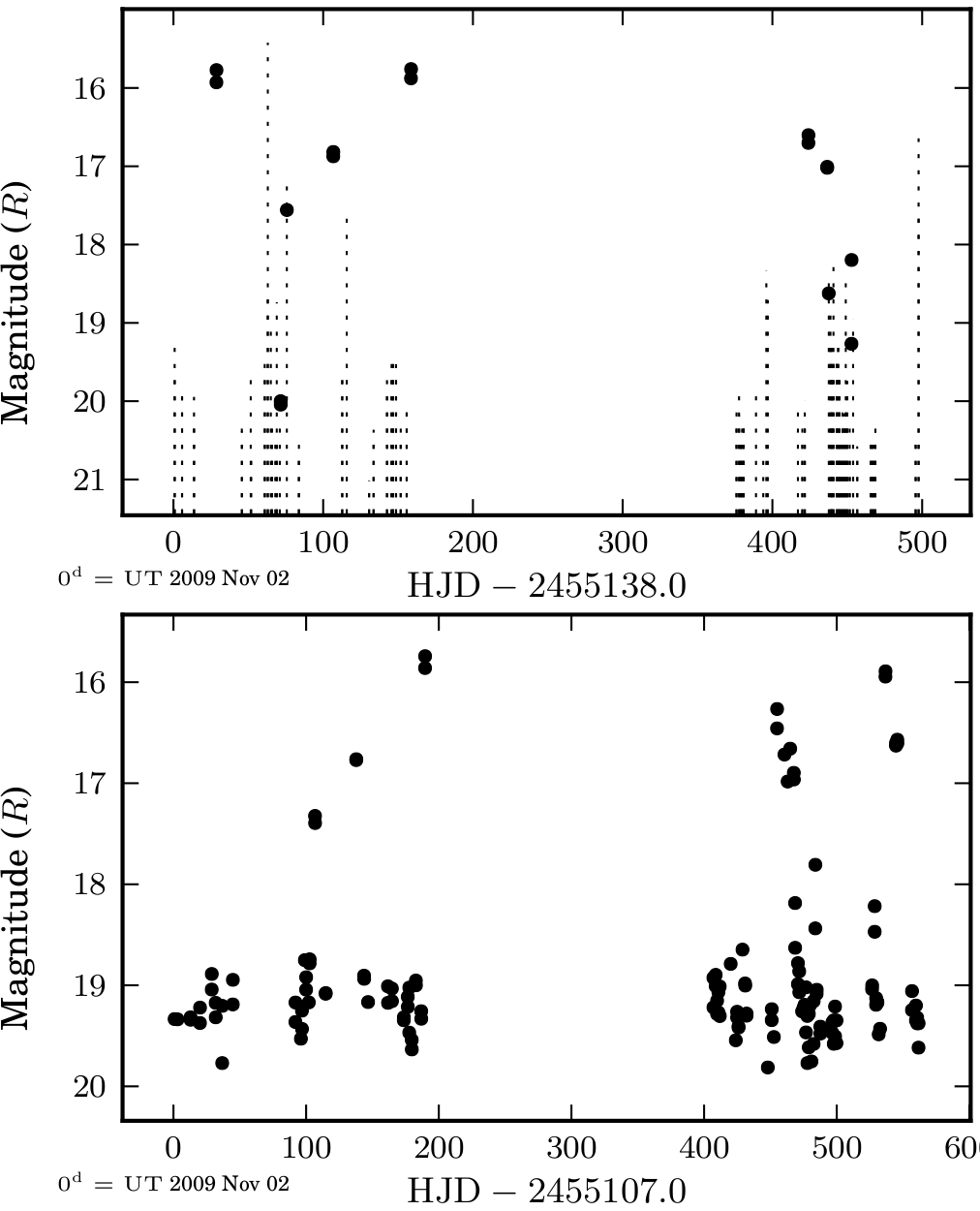
Bottom: PTF Photometric Light Curve of Same Object
I work with the photometric pipeline group and am responsible for taking catalogs of source detections and converting them into very accurately calibrated light curves. As a good comparison between the fast pipeline used to find transients and the photometric pipeline, to the left is an example of two light curves of the same source. The top is from the transient pipeline (this is of the AM CVn system PTF1J071912.13+485834.0) and the bottom is from our photometric pipeline. In the top one, the dashed lines show theoreticaly limiting magnitudes - the theoretical limit for how faint an object can be detected. Most of the time the star is not even detected! But in the photometric pipeline, we have good detections in every observation.
Source Classification
We have a lot of data on a good chunk of the sky. So, one of the obvious things we need to do is figure out what types of stars are in the data. It's often possible to classify stars just based on how they vary, and this is something that I hope to work on in the future. For now though, I concentrate on finding the outbursting compact binaries that are the in the data. A limited problem like this is much easier to deal with than trying to classify everything in the data set.